



Go is an amazing language. Though it is notoriously simple, with bare minimal features compare to other modern languages like Koltin and Scala, it has great concurrency capabilities. In this article, we are going to see how we can write a complete concurrent file downloader. You can see the complete working source code here .
Check if the server supports this feature
If you have ever used a download manager software like IDM, you probably noticed that it can download a file concurrently:
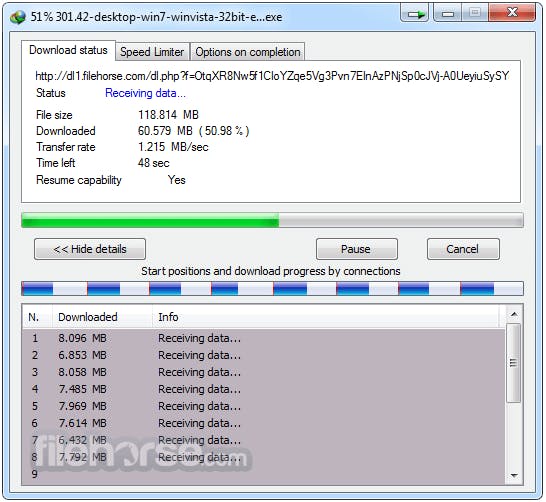 You can see that it has started 8 threats to download the file. In order to download concurrently, we should ensure that the server supports partial request. To do this we can send a HEAD request to the server, and if it returns Accept-Ranges with the value of bytes in the header's response, we know for sure that the server support this feature.
You can see that it has started 8 threats to download the file. In order to download concurrently, we should ensure that the server supports partial request. To do this we can send a HEAD request to the server, and if it returns Accept-Ranges with the value of bytes in the header's response, we know for sure that the server support this feature.
res, err := http.Head("http://some.domain/some.file")
if err != nil {
log.Fatal(err)
}
if res.StatusCode == http.StatusOK && res.Header.Get("Accept-Ranges") == "bytes" {
// Yeh, server supports partial request
}
How to download only part of the file
Imagine that the server accept ranges, and we know the file size is 4000 bytes (from the response header Content-Length). To download only part of the file from 2000 to 3000 bytes we can issue a HTTP GET request with the header Range set:
curl -X GET -H "Range: bytes=2000-3000" -o OUTPUT_FILE http://some.domain/some.file
And here is the equivalent code:
req, err := http.NewRequest("GET", "http://some.domain/some.file", nil)
if err != nil {
log.Fatal(err)
}
rangeStart := 2000
rangeStop := 3000
req.Header.Set("Range", fmt.Sprintf("bytes=%d-%d", rangeStart, rangeStop))
// make a request
res, err := http.DefaultClient.Do(req)
Save the response to a file
In order to support resume functionality, we don't store the HTTP response in the memory, but we persist into a file. If we have set the concurrency level to 4 for example, then there will be 4 temporary files in the output directory. In the below code, we simply read from HTTP response body and write them in a file:
f, err := os.OpenFile(outputPath, flags, 0644)
if err != nil {
log.Fatal(err)
}
defer f.Close()
_, err = io.Copy(f, res.Body)
Pause the download
The above code has a problem, and that is it doesn't respect the user's CTRL+C. If the download file is big, and the network is slow, it takes some time to download. That is because io.Copycopies until either EOF is reached on src or an error occurs. To fix this problem, we use io.CopyN with companion of cancel channel:
// copy to output file
for {
select {
case <- context.Done():
// user canceled the download
return
default:
_, err = io.CopyN(f, res.Body, BUFFER_SIZE))
if err != nil {
if err == io.EOF {
return
} else {
log.Fatal(err)
}
}
}
}
Check the full source code
I mentioned the most important part of the code, but there are a lot of other things that you can read from the code, like the way progress bar works, how I used the sync package in order to wait for partial downloads, how I merged the temporary output files and how I handled resumed functionality. So please check out the repo for more information. I hope you enjoyed reading.