

Tunny is a Golang library for spawning and managing a goroutine pool, allowing you to limit work coming from any number of goroutines with a synchronous API.
A fixed goroutine pool is helpful when you have work coming from an arbitrary number of asynchronous sources, but a limited capacity for parallel processing. For example, when processing jobs from HTTP requests that are CPU heavy you can create a pool with a size that matches your CPU count.
In this tutorial, we will take a visual guide to the implementation details of Tunny and see how it works under the hood. First, read the usage example to get the idea of how it works and then come back here to dig into details. Sounds great? let's start.
What happens when we set the pool size?
Basically, we want a pool of goroutines that can take a job from a queue somehow, process the job, and get back to the pool again when the job has finished. If all the goroutines are busy processing the jobs, new jobs submitted to the pool have to be blocked until a goroutine gets free and picks the job. In Tunny these goroutines are called worker and created in the Pool.SetSize method. If the pool size is N, then we have N workers running concurrently:
func (p *Pool) SetSize(n int) {
// Code omitted for bravity
for i := lWorkers; i < n; i++ {
p.workers = append(p.workers, newWorkerWrapper(p.reqChan, p.ctor()))
}
}
newWorkerWrapper runs each worker in a separate goroutine:
go w.run()
When running each worker,newWorkerWrapper passes a channel called reqChan to each worker.
reqChan chan workRequest
When these workers are free, they send a request to this channel, saying:
Hey, I'm free and I can process a job from the pool
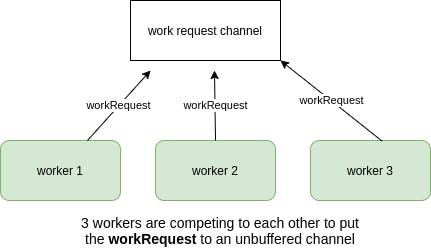
Because this channel is an unbuffered channel, only one worker can write to this channel at any given time:
reqChan: make(chan workRequest)
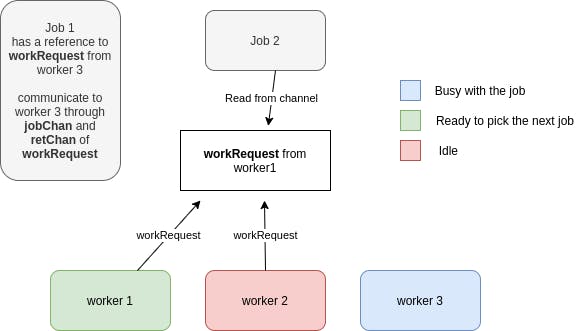
and the other workers have to wait until the channel gets free again. Imagine the pool size is 3, the picture below shows how it works:
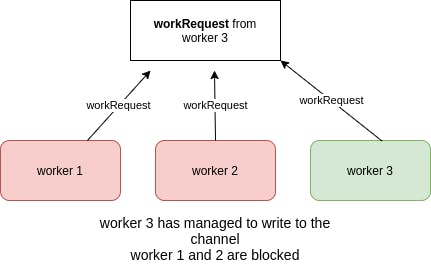
What happens when a job is submited to the pool?
If someone submits a job to the pool, first it reads from reqChan
// this code is part of --> (p *Pool) Process method
request, open := <-p.reqChan
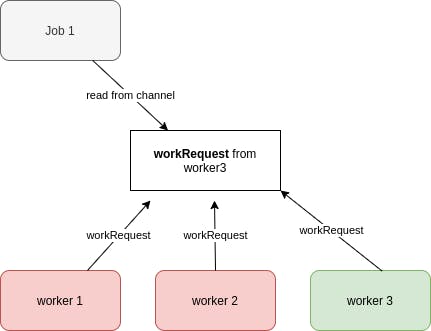 And communicate with the worker through workRequest.
And communicate with the worker through workRequest.
type workRequest struct {
// jobChan is used to send the payload to this worker.
jobChan chan<- interface{}
// retChan is used to read the result from this worker.
retChan <-chan interface{}
}
It passes the input/payload data via jobChan to the worker and waits until the result comes back via retChan:
request.jobChan <- payload
result, open = <-request.retChan
While worker 3 is busy processing the job, the other 2 workers trying to send the workRequest to the channel, because now the channel is free and they can write to it:
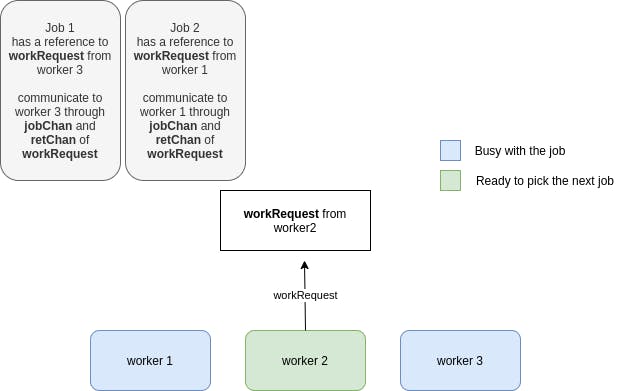
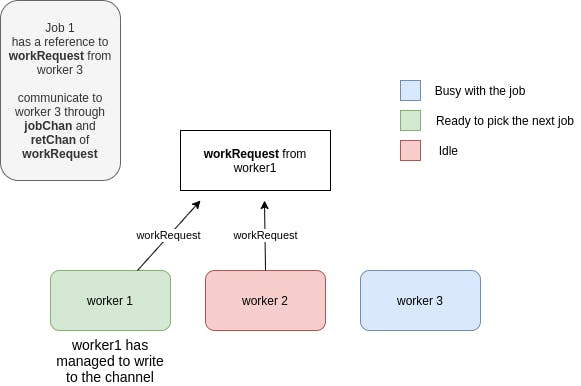 This process repeats for the other jobs submitted to the pool:
This process repeats for the other jobs submitted to the pool:
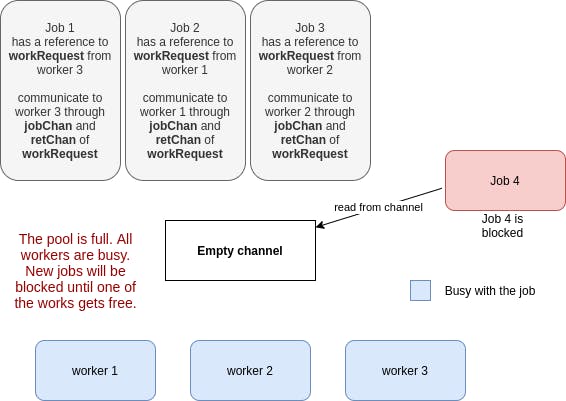
 If all the workers are busy, and a new job comes, it will be blocked, because it tires to read from
If all the workers are busy, and a new job comes, it will be blocked, because it tires to read from reqChan, and the channel is empty, causing it to wait:
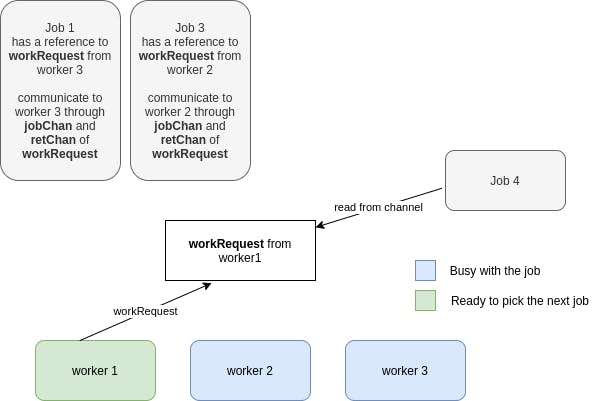
 And eventually, one worker will finish his job and notify his readiness and will pick up the blocked job:
And eventually, one worker will finish his job and notify his readiness and will pick up the blocked job:
Last word
For me, the way that workers voluntarily declare I'm free and I can pick a job was interesting. The project is popular and I was curious to know about the project. That's why after I understood how it works, I shared it with you.